library(tidyverse)
library(haven)
library(knitr)
hoorn <- read_sav("data/Hoorn.sav") |>
select(gender, mar_st, sbp1s) |>
mutate(across(where(is.labelled), haven::as_factor)) # labelled class omzetten naar factor2 Het vergelijken van groepen
2.1 Introductie
In deze video gaan we naar de eerste paar technieken kijken die gebruikt kunnen worden voor inferentiële statistiek. We gaan specifiek kijken naar analyses waarmee twee of meerdere (categoriale) groepen met elkaar vergeleken kunnen worden. De analyses die hier aan bod komen vallen onder de zogeheten ‘parametrische’ toetsen: toetsen die op basis van een onderliggend kansmodel worden gedaan.
De volgende komen aan bod:
T-toetsen voor het vergelijken van een kwantitatieve uitkomstvariabelen tussen twee groepen
One-way ANOVA voor het vergelijken van een kwantitatieve uitkomstvariabele tussen twee of meer groepen
Chi-square toets voor het vergelijken van een categoriale uitkomstvariabele tussen twee of meer groepen
Per toets zullen we ook kort kijken naar de assumpties die de toets maakt en hoe je deze kunt toetsen. Voor alle toetsen maken we de aanname dat de observaties onderling onafhankelijk zijn. Op basis van alleen de data kan deze assumptie niet gecontroleerd worden. Houdt er dus rekening mee dat als je je eigen gegevens gaat analyseren dat je onderbouwd of deze assumptie aannemelijk is of niet! Als blijkt dat je aan bepaalde assumpties helemaal niet voldoet, dan kan je uitwijken naar zogeheten non-parametrische toetsen, ook wel ‘verdelingsvrije’ toetsen genoemd. Deze toetsen worden in een andere video besproken.
De benodigde packages zijn tidyverse en haven. Voor alle analyses maken we weer gebruik van de Hoorn dataset. We hebben maar vier variabelen nodig: systolische bloeddruk 1e meting (sbp1s), geslacht (gender) en huwelijksstaat (mar_st). Met behulp dplyr kunnen we de beoogde kolommen selecteren.
2.2 Parametrische toetsen
2.2.1 T-toetsen
Er bestaan drie soorten T-toetsen, de één-steekproef T-toets, de gepaarde T-toets en de twee steekproeven T-toets. Wij gaan hier naar de laatste kijken, waarbij we de gemiddelden van de twee groepen tegen elkaar kunnen toetsen. We toetsen dus een kwantitatieve (continue) uitkomst voor een dichotome (nominale) determinant. Er zijn twee assumpties (naast onafhankelijke observaties):
De steekproefgemiddelden zijn bij benadering normaal verdeeld
De varianties zijn in de te vergelijken populaties homogeen
De normaliteit kunnen we beoordelen door bijvoorbeeld een histogram voor beide groepen te maken. Noramliteitstoetsen bestaan ook, maar wij raden doorgaans aan om normaliteit a.d.h.v. een plaatje te beoordelen. Normaliteitstoetsen zijn vaak ‘overpowered’ wat inhoudt dat ze snel significant uit vallen bij grotere steekproeven, zelfs als de afwijking van normaliteit maar heel klein is.
ggplot(hoorn,
aes(x = sbp1s, fill = gender)) +
geom_histogram(bins = 15) +
facet_wrap(~ gender)Warning: Removed 1 row containing non-finite outside the scale range
(`stat_bin()`).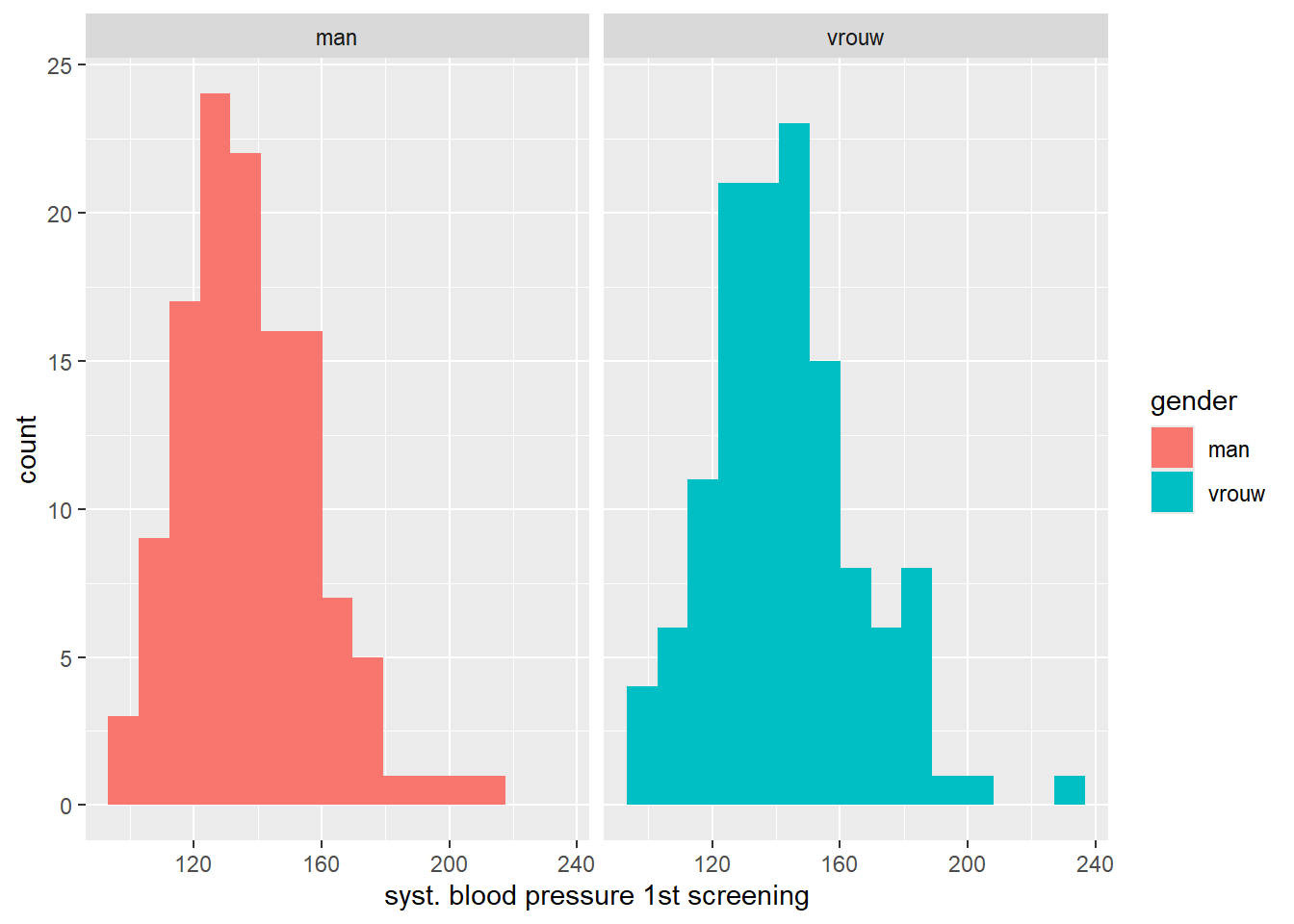
Je kunt een beetje spelen met het aantal bins, waarvan ik er in dit geval 15 gemaakt heb. We zien voor beide groepen wat uitschieters aan de hogere waarden van systolische bloeddruk. Met name bij mannen lijkt de verdeling ietwat rechtsscheef, maar niet heel extreem. Daarnaast bestaan beide groepen uit ongeveer 125 proefpersonen, waarmee we prima van de centrale limietstelling uit kunnen gaan. Aan de assumptie van normaliteit voldoen we doen.
Homogeniteit van varianties kunnen we bekijken door de standaarddeviaties van bloeddruk in beide groepen te vergelijken, of door een boxplot te maken voor beide groepen.
ggplot(hoorn,
aes(y = sbp1s, x = gender, fill = gender)) +
geom_jitter(alpha = 0.2, width = 0.1) +
geom_boxplot(width = 0.5, outliers = F) Warning: Removed 1 row containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_point()`).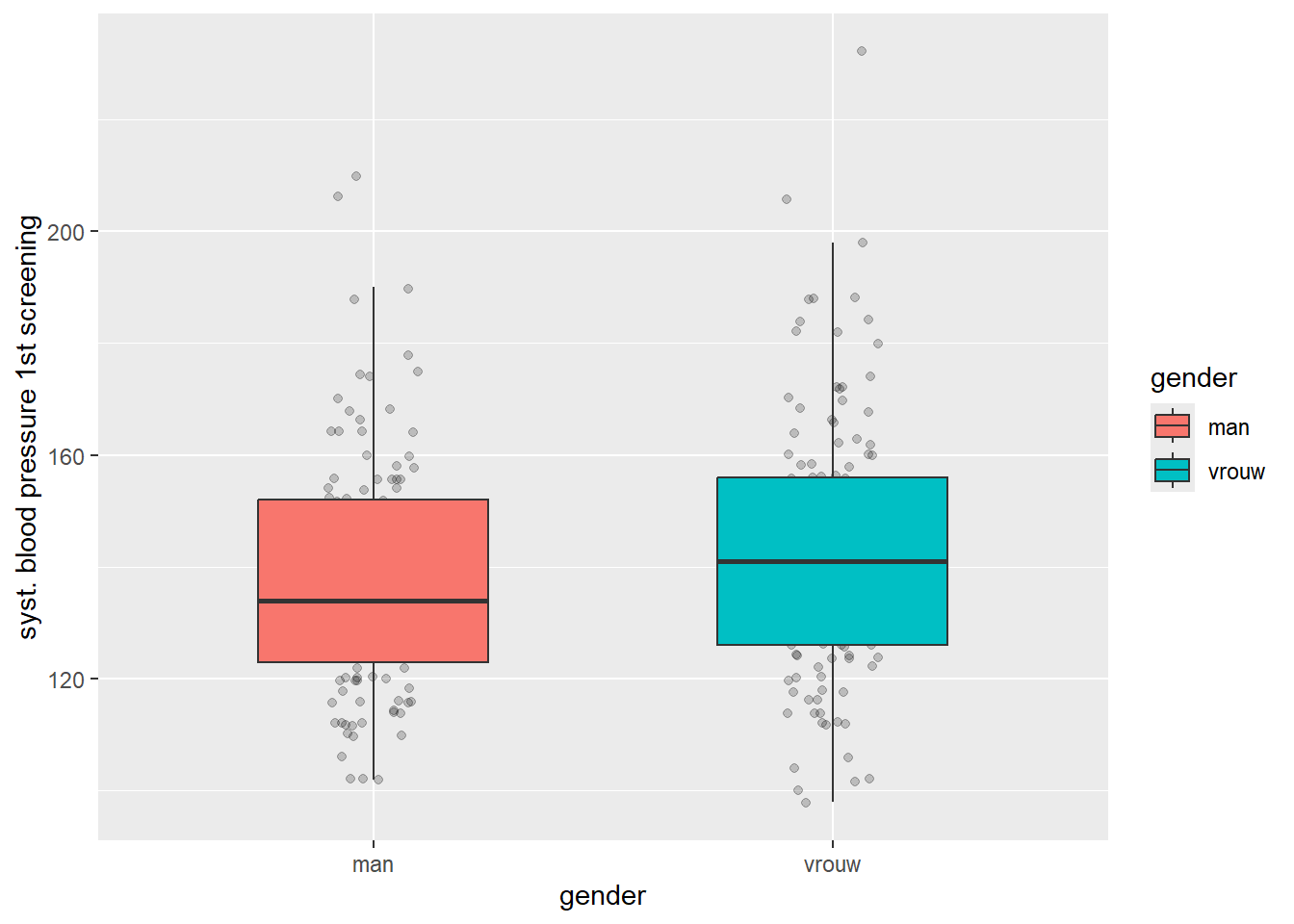
Hierboven zien we dat de ‘lengte’ van beide boxplots ongeveer gelijk zijn. De varianties in beide steekproeven zijn vergelijkbaar, en dus concluderen we dat de populatievarianties dat waarschijnlijk ook wel zijn. Ook hier bestaat een toets voor, de zogeheten toets van ‘Welch’. Ook deze raden we over het algemeen niet aan om dezelfde redenen als de normaliteitstoetsen. Tevens bestaat er voor de T-toets een variant die je kunt gebruiken als je niet voldoet aan de eis voor homogeniteit. Deze heet de ‘Welch aangepaste T-toets’, en brengt een correctie aan op basis van hoe sterk de varianties afwijken van elkaar.
Sidenote: In de boxplot heb ik een extra geom toegevoegd: geom_jitter(), wat een variatie is van de geom_point(). Deze voegt in dit geval wat horizontale ruis toe, waardoor de puntjes niet op één lijn liggen en dus beter zichtbaar zijn. Het is niet noodzakelijk, maar soms kan het handig zijn. Met de argumenten alpha en width kun je respectievelijk de ‘doorzichtigheid’ en horizontale afstand van de puntjes instellen.
Laten we nu de T-toets uitvoeren! Dit doen we met t.test(), waar we een formule moeten invoeren en uiteraard de data als argument toevoegen. De formule ziet er in dit geval als vogt uit: sbp1s ~ gender, waarbij bloeddruk de uitkomst, en gender de determinant is.
t.test(sbp1s ~ gender, data = hoorn)
Welch Two Sample t-test
data: sbp1s by gender
t = -1.7217, df = 245.18, p-value = 0.08638
alternative hypothesis: true difference in means between group man and group vrouw is not equal to 0
95 percent confidence interval:
-10.4491015 0.7019083
sample estimates:
mean in group man mean in group vrouw
138.3089 143.1825 We zien dat zonder enige argumenten, R automatisch de Welch T-toets toepast. We kunnen dit eventueel handmatig aanpassen naar de T-toets waarin gelijke varianties verondersteld worden met het argument var.equal = TRUE. In de praktijk is het in onze optiek echter verstandiger om de Welch gecorrigeerde T-toets te doen, zelfs als de varianties gelijk lijken te zijn. In veel gevallen verschillen de resultaten ook niet al te veel.
Vanuit de T-toets zien we dat het geschatte verschil in bloeddruk tussen mannen en vrouwen 138.31 - 143.18=-4.87. Het gevonden verschil is niet significant, te zien aan de p waarde van 0.086 die boven de gebruikelijke \(\alpha=0.05\) ligt. We kunnen dat ook concluderen a.d.h.v. het 95% betrouwbaarheidsinterval wat van -10.45 tot 0.70 loopt, en de 0 bevat.
Oefening: Voer de T-toets eens uit met veronderstelling van gelijke varianties. Wat zijn de verschillen? Is de conclusie anders?
2.2.2 One-way ANOVA
Als we meer dan twee groepen willen vergelijken, kunnen we gebruik maken van de one-way ANOVA (ANalysis Of VAriance), of ook wel variantieanalyse genoemd. Voor de variantieanalyse gelden in principe dezelfde assumpties als de T-toets, en is er ook weer een Welch gecorrigeerde variant die we kunnen gebruiken als de populatievarianties niet gelijk zijn. We gebruiken nu huwelijksstaat (mar_st) als determinant, welke uit 5 categorieën bestaat. Eerst eens naar de boxplots kijken:
hoorn |> filter(!is.na(mar_st)) |>
ggplot(aes(x = mar_st, y = sbp1s, fill = mar_st)) +
geom_jitter(alpha = 0.2, width = 0.2) +
geom_boxplot(alpha = 0.5)Warning: Removed 1 row containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_point()`).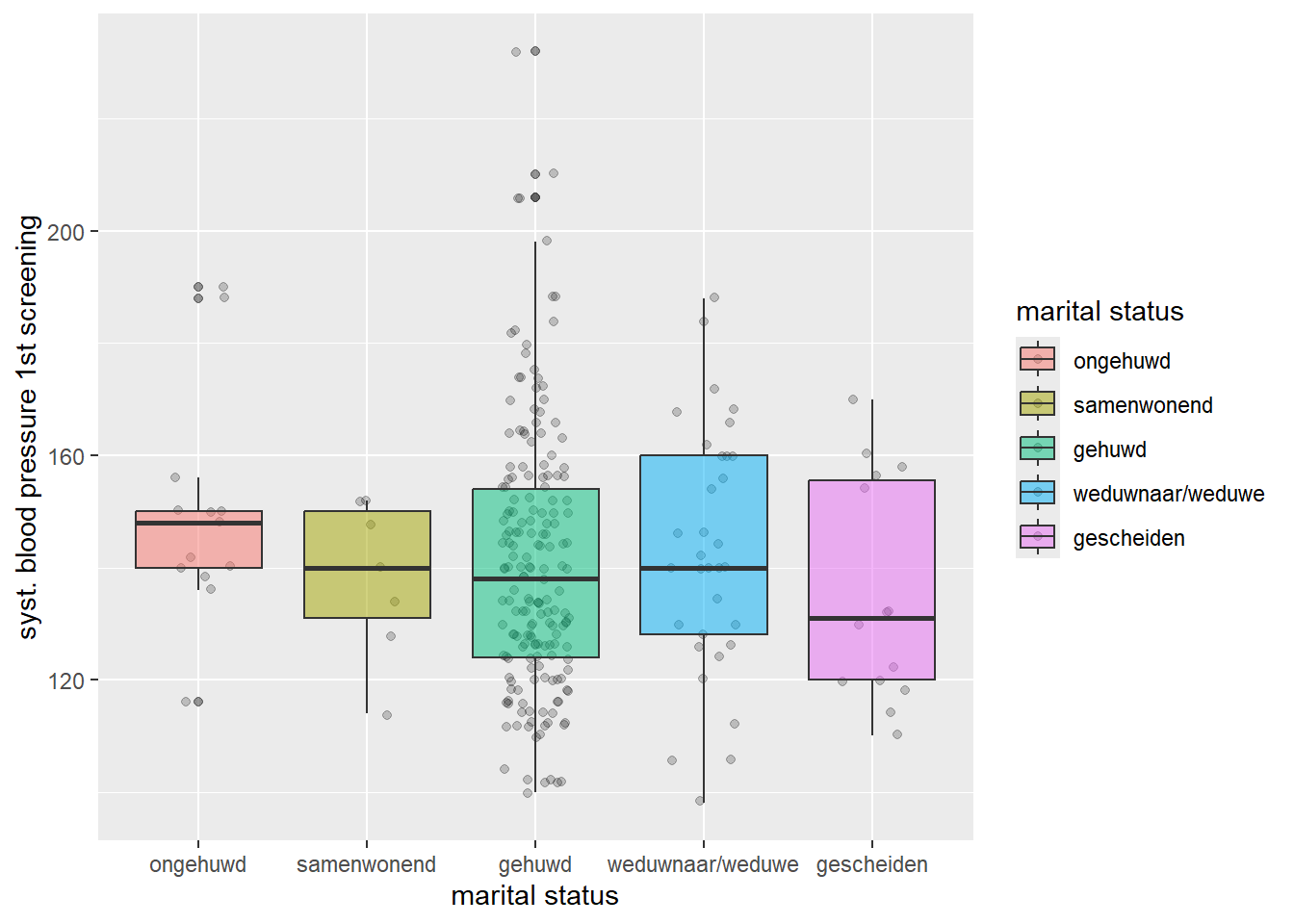
De verdeling van de boxplots ziet er volgens de boxplots wat grillig uit voor sommige categorieën. Dat komt doordat de grote meerderheid gehuwd is, en slechts een klein deel iets anders. Het is dus verstandiger om niet van gelijke varianties, maar misschien ook niet van normaliteit uit te gaan… van de CLS kunnen we met zulke kleine steekproefgrootten niet zomaar uit gaan.
Sidenote: Ik maak hier gebruik van de ‘pipe’ voordat ik ggplot() aanroep, dat doe ik om de ene missende waarneming van mar_st eruit te halen, die anders een eigen boxplot krijgt en niet zo veel toevoegt in dit geval. Het filter(!is.na(mar_st) functie zorgt ervoor dat alle waarnemingen die niet NA zijn meegenomen worden in de opvolgende (dus ggplot()) functie.
Dan de ANOVA! Deze kan je met de oneway.test() functie uitvoeren, en werkt in principe exact hetzelfde als de t.test(), waarbij we minimaal een formule moeten invoeren en de data waarmee we willen toetsen.
oneway.test(sbp1s ~ mar_st, data = hoorn)
One-way analysis of means (not assuming equal variances)
data: sbp1s and mar_st
F = 0.94368, num df = 4.000, denom df = 25.955, p-value = 0.4546We zien dat ook hier de standaard procedure ongelijke varianties verondersteld, die we ook weer handmatig kunnen omzetten met var.equal = TRUE. Aan de p waarde (die boven de 0.05 ligt) kunnen we zien dat we geen verschillen in systolische bloeddruk aan hebben kunnen tonen tussen de verschillende huwelijksstaten. We dienen hier wel rekening te houden met het feit dat zeker drie van de categorieën veel te weinig datapunten én grillige verdelingen hebben… de statistische conclusies zijn dus niet erg betrouwbaar.
2.2.3 Chi-kwadraattoets
De laatste parametrische toets waar we naar kijken is de Chi-kwadraattoets. Deze toets kunnen we gebruiken als we een categoriale uitkomst én categoriale determinant hebben. In ons geval kunnen we hiermee dus bepalen of huwelijksstaat en gender een geassocieerd zijn met elkaar. De Chi-kwadraattoets wordt vaak gebruikt met behulp van een kruistabel. Er zijn twee voorwaarden:
80 procent van de cellen van de kruistabel moet een verwachtte celfrequentie van 5 of hoger hebben
Géén van de cellen van de kruistabel mag een verwachtte celfrequentie van 1 of lager hebben
Om de Chi-kwadraattoets uit te voeren maken we eerst een kruistabel met table(). Dat doen we door de variabelen uit de dataset als argumenten in te voeren. Dit doen we door hoorn$gender en hoorn$mar_st in te vullen. We slaan de tabel op in het object crosstab, omdat we deze zo nog nodig hebben.
crosstab <- table(hoorn$mar_st, hoorn$gender)
crosstab
man vrouw
ongehuwd 8 5
samenwonend 3 4
gehuwd 98 84
weduwnaar/weduwe 6 27
gescheiden 7 7We zien in de tabel de geobserveerde frequenties: hier zien we o.a. dat de groep gehuwde mensen voor zowel mannen als vrouwen vrij groot zijn. Om nu de voorwaarde te controleren, kunnen we het beste de Ch-kwadraattoets uitvoeren en opslaan in een object dat we test noemen. Vervolgens halen we uit het nieuwe object de verwachtte frequenties met test$expected.
test <- chisq.test(crosstab)Warning in chisq.test(crosstab): Chi-squared approximation may be incorrecttest$expected
man vrouw
ongehuwd 6.369478 6.630522
samenwonend 3.429719 3.570281
gehuwd 89.172691 92.827309
weduwnaar/weduwe 16.168675 16.831325
gescheiden 6.859438 7.140562We zien dat we nét aan voldoen aan de assumpties: precies 80 procent van de cellen (8 van de 10) heeft een verwachtte celfrequentie van boven de 5. Aangezien we hier zo dichtbij zitten, geeft R aan dat de Chi-square benadering mogelijk incorrect kan zijn. We kunnen hier dus misschien beter een non-parametrisch alternatief toepassen. Laten we toch nog even naar het resultaat kijken:
test
Pearson's Chi-squared test
data: crosstab
X-squared = 15.181, df = 4, p-value = 0.004339We zien dat de p waarde onder de 0.05 ligt, wat betekent dat het resultaat statistisch significant is. We kunnen dus concluderen dat er een verband bestaat tussen gender en huwelijksstaat. We moeten hier wel de kanttekening bijplaatsen dat we nét aan voldoen aan de assumpties.